XSS系列(1)——XSS基础知识
俗话说:「万丈高楼平地起」「不积跬步无以至千里」。
学习任何专业,基础知识非常的重要。基础知识是否扎实,决定了你能走多远。
目前网络上关于XSS的知识、介绍非常的多,成系统、系列的介绍却不多。本文争取集各家之所长,由浅及深的介绍XSS的相关知识。本文是XSS系列第一篇,先来介绍XSS相关的基础知识。因小弟才疏学浅,不足之处还望各位大佬多多指教。
本文参考了很多大佬的分享原作,在此表示感谢。我只是一个知识的搬运工。
0x01 浏览器编码
提到XSS,便不得不讲浏览器编码。浏览器编码虽不复杂,却也有许多细节之处常常被人忽略,而对于细节的掌握和理解是否到位,决定了有时候能否成功的编写一个XSS poc。
下面简单介绍下各类的编码类型。
1. 编码类型
浏览器在解析HTML时,是按照一定的格式和编码来解析的,为了不扰乱HTML结构,有HTML编码(比如:<对应<);为了不扰乱JS的语法,有JS编码(比如:'对应\'),为了正常解析URL,有URL编码(比如:&对应%26)。总结起来也就三类,但是有不同的编码形式。
在呈现HTML页面时,针对某些特殊字符如<或>直接使用,浏览器会误以为它们标签的开始或结束,若想正确的在HTML页面呈现特殊字符就需要用到其对应的字符实体。
1.1 HTML编码
HTML编码形式最常见的有三种:别名形式、16进制形式、10进制形式,比如:<>"'采用这三种方式编码后分别如下:
- 字符编码(别名形式):
<>"' - 16进制形式:
<>"' - 10进制形式:
<>"'
HTML编码的这几种方式可以混合出现,浏览器都可以正常解析。
上述三种形式的分号均可以省略。
1.2 JS编码
JS编码形式最常见的有四种:斜杠转义形式、16进制形式、Unicode编码形式。<>"'采用这几种方式编码后分别如下:
斜杠转义形式:\<\>\"\'
16进制形式:\x3c\x3e\x22\x27
Unicode编码形式:\u003c\u003e\u0022\u0027
注意:
- 在Unicode编码形式中,中间的字符可以是1-7个字符。如
\u000003c。但是笔者在用最新版的Chrome浏览器中测试的时候,只有四个字符可以被正确的识别。各种缘由,暂不清楚。 - 这几种方式也可以混合出现。
- 一般的斜杠转义形式不对字母、数字进行转义,因为可能出现混乱的情况,比如:\x\3\c并不会按想象中那样解析成x3c,而是会报语法错误。
1.3 URL编码
URL编码估计大家都非常熟悉,编码都采用%XX的形式,比如同样的<>"'经URL编码后得到%3C%3E%22%27。
需要注意的是,URL编码可以细分为encodeURI,encodeURIComponent两种编码形式,下面将简单说明一下两周编码形式的区别。
encodeURI
encodeURI 是用来处理整个 URI 的,它应该接受 URI 的 protocol, host, port以及URL中的功能字符&?/= 等部分,只对 path 和 query 进行编码。
如果 POST 请求的 Request Header 中 Content-Type 为「application/x-www-form-urlencoded」, 那么 Request Payload 里面的数据一般就是使用 encodeURI(Component) 编码的。
encodeURIComponent
encodeURIComponent 对所有的字符均编码。
举例
1 | encodeURI('https://www.baidu.com/ a b c') |
其实除了以上两种URL编码外,还有escape编码,但因为escape已经从 Web 标准中删除,所以此处不做介绍。
2. 编码位置
HTML页面中我们可以按照指定的编码格式去编码,但是,必须要在合适的位置用合适的编码,以及符合浏览器的解码规则和顺序,否则浏览器也无法识别。
2.1 HTML编码适用位置
HTML编码适用于属性值、标签内的内容,看如下示例:

浏览器解析后如下图:
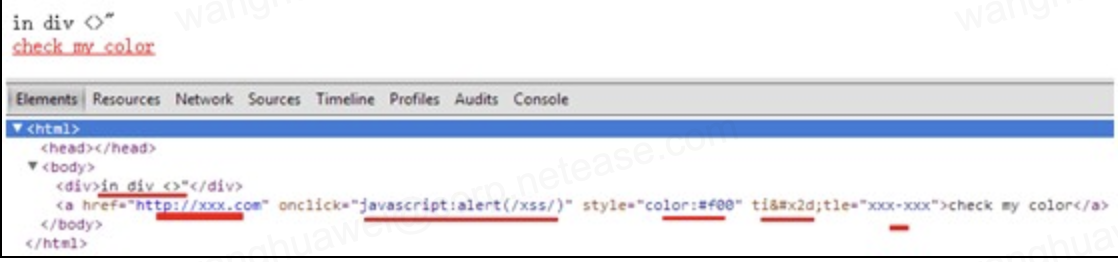
可以看到:
- 标签内使用html编码,被解析出来了,并且不影响DOM结构。
- 属性值使用html编码,被解析出来了,并且在url、js事件、css中也是如此。
- 属性名使用html编码,没有被解析出来
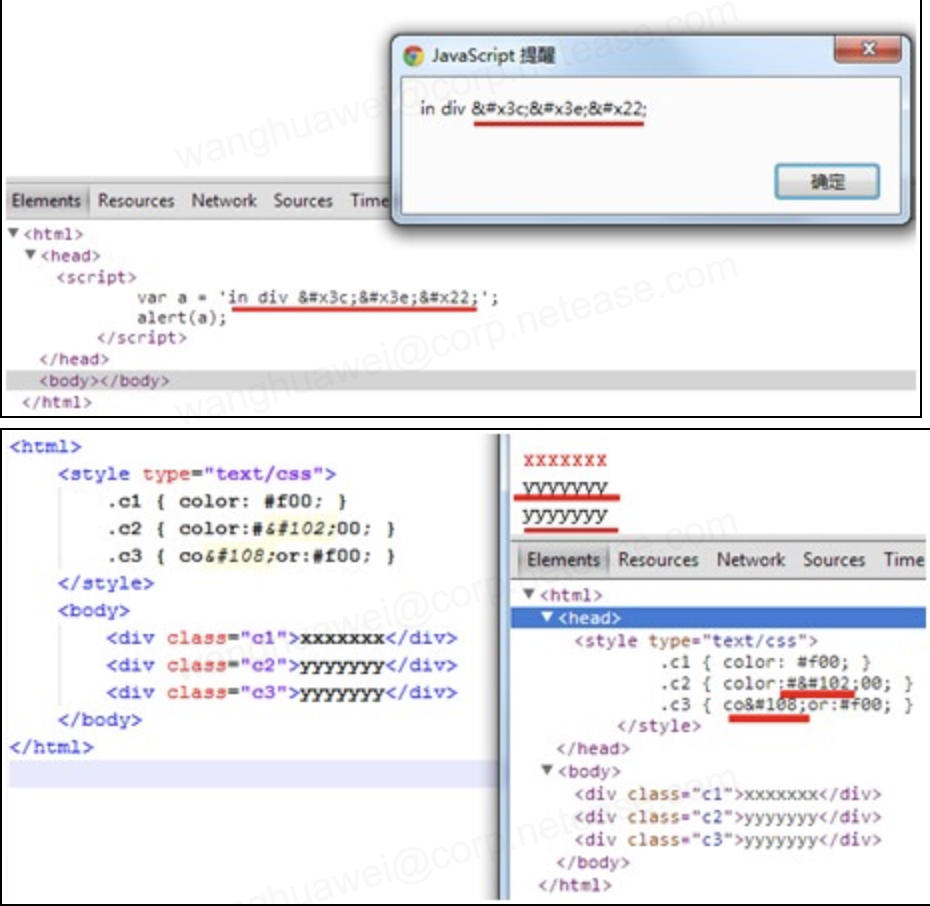
但是,在<script>标签内的js内容以及<style>中的css内容,浏览器是不会使用html编码解码的:
2.2 JS编码适用位置
JS编码则只适用于JS代码中,包括<script>内和JS事件中:
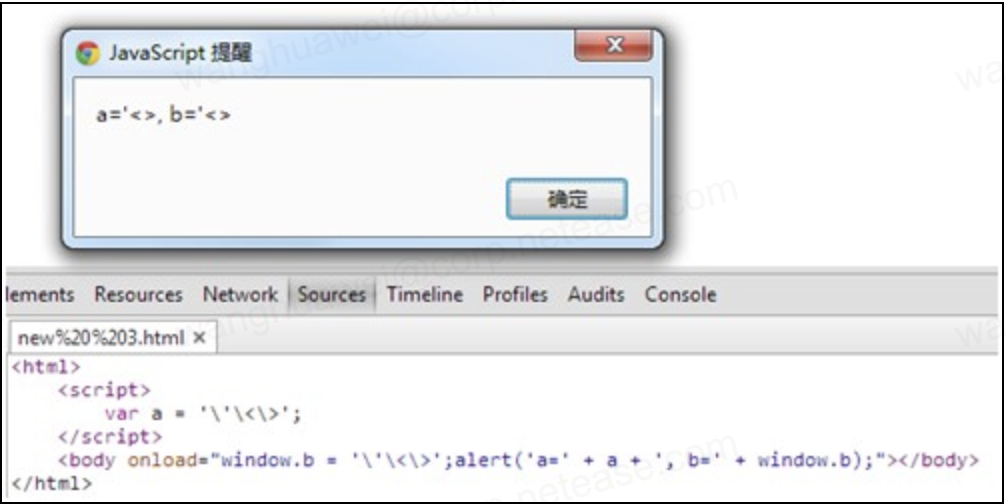
对于JavaScript,转义编码应当只出现在标示符部分,不能用于对语法有真正影响的符号,也就是括号,或者是引号。所以,对('')等进行js编码是失败的。
示例代码:
1 | <script> |
可以对dafaf施行16进制编码Unicode编码形式以及斜杠转义形式
只可以对alert施行Unicode编码
不能对('')编码
我们来分析一下JavaScript解析的一个细节,Javascript解析器工作的时候将\u0061\u006c\u0065\u0072\u0074进行js解码后为“alert”,而“alert”是一个有效的标识符名称,它是能被正常解析的。像圆括号、双引号、单引号等等这些控制字符,在进行JavaScript解析的时候仅会被解码为字符串文本或者上面讲的标识符名称,例如:<script>alert('LDkR\u0027)</script>对控制字符单引号进行js编码,解析时\u0027被解码成文本单引号,无法闭合因此不能成功执行。
2.3 URL编码适用位置
URL编码则只适用于为URL的属性值,且只能对URL中的参数进行URL编码。比如:<a>标签的href属性、<iframe>的src属性等。
3. 浏览器解析顺序
既然各个编码有适合自己的位置,并且这种位置必定会重合,所以,浏览器解码必定有一定的顺序。
首先浏览器接收到一个HTML文档时,会触发HTML解析器对HTML文档进行词法解析,这一过程完成HTML解码并创建DOM树,接下来JavaScript解析器会介入对内联脚本进行解析,这一过程完成JS的解码工作,如果浏览器遇到需要URL的上下文环境,这时URL解析器也会介入完成URL的解码工作,URL解析器的解码顺序会根据URL所在位置不同,可能在JavaScript解析器之前或之后解析。
浏览器无论什么情况都会遵守一个这样的解码规则:
1、 HTML 解析器对 HTML 文档进行解析,完成 HTML 解码并且创建 DOM 树
2、 JavaScript 或者 CSS 解析器对内联脚本进行解析,完成 JS、CSS 解码
3、 URL 解码会根据 URL 所在的顺序不同而在 JS 解码前或者解码后
下面,讲距离几个具体的例子,对解码顺序做一些说明,以方便理解和记忆。
3.1 解码举例1
1 | <html> |
一个正常的容易理解的过程是这一行:
1 | <img src=# onerror="alert(1)" /> |
HTML 解析到标签,建立DOM 树,然后对节点内容进行实体解码,a; 就变成a, 随后在js 解析阶段,正常的触发了弹窗,先后顺序OK。
但对于下面这段代码:
1 | <script> |
使用了DOM 操作,修改前边标签中的内容,添加了一个img 内容,因为进入了script 进入了JavaScript的特殊解析模式,所以此处HTML 不得干扰,首先JavaScript解析器,会先对其中编码的内容解码,于是onerror 就还原回来了,于是正常的执行了JS 语句,在HTML 文档中,将hello 变成了img。img标签内容变成了:
<img src=# onerror=alert(1)>该标签传回给HTML,HTML 建立DOM节点,HTML解码节点内容:
<img src=x onerror=alert(1)>onerror 又会执行其中的JS 脚本,弹出窗口。
其实,这里也不难理解,因为HTML 是从上到下解析,遇到< script> 于是进入了特殊的解析模式,使用JS 解析器,做了一个DOM 操作,该DOM 操作修改了前边的DOM 树,该块内容,需要使用HTML 解析重塑DOM 树,那么节点内容中的实体编码就会被解码,然后onerror 中触发脚本,JS 又会对内容进行一次解析。
总结说来,实际上,DOM 操作实际上是js强势介入 HTML 和CSS 的结果,使用DOM 操作,对DOM Tree 造成了改变,会调用到HTML 解析器重新对其解析,于是流程又会返回到最开始说的那个解析流程里去。
3.2 解码举例2
1 | <a href="javascript:alert(1)">test</a> |
针对上述a标签我们分析一下该环境中浏览器的解析顺序,首先HTML解析器开始工作,并对href中的字符做HTML解码,接下来URL解析器对href值进行解码,正常情况下URL值为一个正常的URL链接,如:“https://www.baidu.com“,那么URL解析器工作完成后是不需要其他解码的,但是该环境中URL资源类型为JavaScript,因此该环境中最后一步JavaScript解析器还会进行解码操作,最后解析的脚本被执行。
整个解析顺序为3个环节:HTML解码 –> URL解码 –> JS解码
变形1:URL编码 javascript:alert(1)
1 | URL编码“javascript:alert(1)”=“%6A%61%76%61%73%63%72%69%70%74:%61%6C%65%72%74%28%31%29” |
需要注意的是,该脚本并不会被正常的执行。这里就有一个URL解析过程中的一个细节了,不能对协议类型进行任何的编码操作,否则URL解析器会认为它无类型,就导致被编码的“javascript”没有解码,所以不会被URL解析器识别。
变形2:
1 | HTML编码"javascript"="javascript" |
HTML解析器工作时,href里的HTML实体会被解码。变成
<a href="javascript:%61%6C%65%72%74%28%32%29"接下来URL解析器工作解析href属性里的链接时,”javascript”协议在第一步被HTML解码了,这样URL解析器是可以识别的,然后继续解析后面的”%61%6C%65%72%74%28%32%29”,变成
<a href="javascript:a lert(1)">最后JavaScript解析器完成解析操作,脚本执行。
变形3:
1 | 对<a href="javascript:alert(3)">test3</a>做JS编码>URL编码>HTML编码共3层。 |
按照上面的逻辑分析,是可以被正常解析之行的。
3.3 解码举例3
1 | <a href=# onclick="window.open('UserInput')"></a> |
- 首先由 HTML 解析器对UserInput 部分进行字符实体解码;
- 接着由 JavaScript 解析器会再对 onclick 部分的 JS 进行解析并执行 JS;
- 执行 JS 后window.open(‘UserInput’)函数的参数会传入 URL,所以再由 URL 解析器对 UserInput 部分进行解码。
解析顺序为:HTML 解析->JavaScript解析->URL 解析。
3.4解码举例4
1 | <a href="javascript:window.open('UserInput')"> |
- 首先还是由 HTML 解析器对 UserInput 部分进行字符实体解码;
- 接着由 URL 解析器解析 href 的属性值;
- 然后由于Scheme为javascript,所以由 JavaScript 解析;
- 解析执行 JS 后window.open(‘UserInput’)函数传入 URL,所以再由 URL 解析器解析。
解析顺序为:HTML 解析->URL解析->JavaScript 解析->URL 解析。
3.5 解码举例5
1 | <a href="javascript:%5c%75%30%30%36%31%5c%75%30%30%36%63%5c%75%30%30%36%35%5c%75%30%30%37%32%5c%75%30%30%37%34(15)"></a> |
首先 HTML 解析器进行解析,解析到href 属性的值时,状态机进入属性值状态(Attribute Value State),该状态会解码字符实体;
接着由 URL 解析器进行解析并解码;
再接着由于 Scheme 为javascript,因此由 JavaScript 解析器解析并解码,加上编码部分是函 数名,属于标识符,因此可以正常解码解释;
4.哪些地方可以触发JS解析器
- 直接嵌入< script> 代码块。
- 通过< script sr=… > 加载代码。
- 各种HTML CSS 参数支持JavaScript:URL 触发调用。
- CSS expression(…) 语法和某些浏览器的XBL 绑定。
- 事件处理器(Event handlers),比如 onload, onerror, onclick等等。
- 定时器,Timer(setTimeout, setInterval)
- eval(…) 调用。